Topper kunstig intelligens i kanten
CEVA er på hugget for tiden. Nå hevder de at de har redefinerer kunstig intelligens innen kantprosessering, med sin nye heterogene og sikre NeuPro-M prosessorarkitektur, blant annet med skalerbar ytelse fra 10 til 1200 TOPS.

Publisert
Denne artikkelen er 2 år eller eldre
CEVA, Inc. lanserte i forrige uke NeuPro-M, som er deres nyeste prosessorarkitektur for inferensarbeidsoppgaver innen kunstig intelligens og maskinlæring (AI/ML).
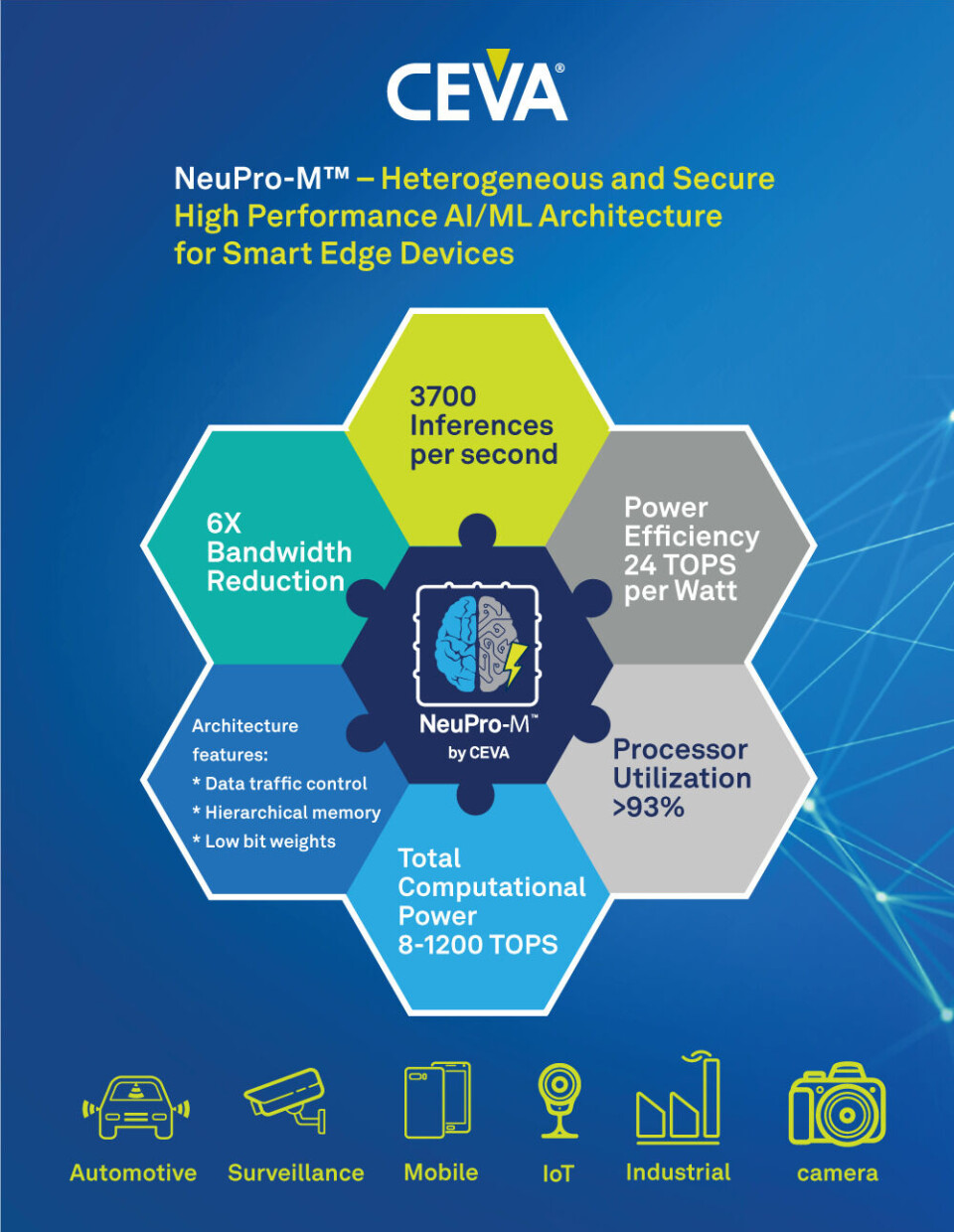
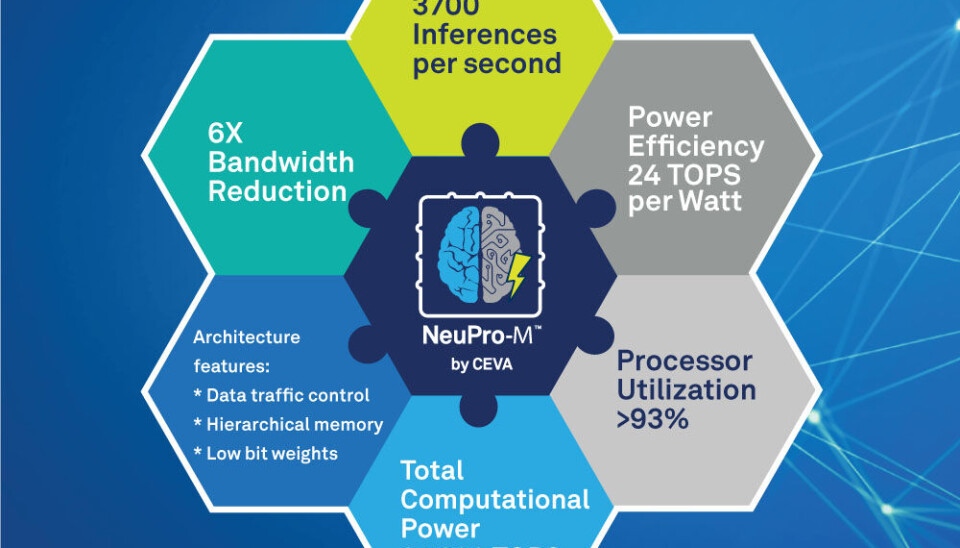
NeuPro-M er rettet mot de store markedene innen kant-AI og kantprosessering, og er en heterogen arkitektur bygget opp av flere spesialiserte koprosessorer og konfigurerbare maskinvareakseleratorer som skal kunne prosessere ulike oppgaver innen dype nevrale nettverk, på en sømløs og parallellisert måte. Arkitekturen skal gi en ytelsesforbedring på 5 til 15 ganger bedre enn forgjengeren.
Som industriens første skal NeuPro-M støtte skalerbarhet både for systembrikker (SoC) og heterogene systembrikker (HSoC) med mulighet til å oppnå hele 1.200 TOPS (tera operasjoner per sekund) og tilbyr dessuten muligheter for robuste og sikre oppstarts funksjoner og ende-til-ende datasikkerhet.
NeuPro–M kompatible prosessorer inkluderer i utgangspunktet følgende forhåndskonfigurerte kjerner:
- NPM11 – enkel NeuPro-M motor, opp til 20 TOPS ved 1,25 GHz
- NPM18 – åtte NeuPro-M motorer, opp til 160 TOPS ved 1,25 GHz
For å illustrere ytelsen, opplyser CEVA at en enkelt NPM11 kjerne ved prosessering av et , ResNet50 konvolusjonelt nevralt nettverk oppnår en ytelsesforbedring som er 5 ganger bedre, samt en reduksjon i minnebåndbredde på 6 ganger, i forhold til sin forgjenger – noe som resulterer i en effektivitet på opp til 24 TOPS per watt. Kort sammendrag av NeuPro-M arkitekturen:
- Hovedmatrise bestående av 4K MACs (Multiply And Accumulates), med variert presisjon på 2-16 bits
- Winograd transformeringsmotor for vekter og aktiveringer, som skal halvere konvolusjonstiden og tillate 8-bit konvolusjonsprosessering med mindre enn 0,5 % presisjonsavvik
- Sparsitetsmotor for å unngå operasjoner med null-verdi vekter eller aktiveringer per lag, for opp til 4 ganger ytelsesforbedring, samtidig som man reduserer minnebåndbredde og effektforbruk
- Fullt programmerbar vektorprosesseringsenhet, for håndtering av nye, ustøttede nevrale nettverksarkitekturer med alle datatyper, fra 32-bit flyttall og ned til 2-bit Binary Neural Networks (BNN)
- Konfigurerbar vekt- og datakomprimering ned til 2 bits under lagring til minne, og sanntids dekomprimering ved utlesning, for redusert minnebåndbredde
- Dynamisk konfigurert to-nivå minnearkitektur for å minimalisere effektforbruket i forbindelse med dataoverføring til og fra ekstern SDRAM.





























